OpenAI parle d’un « niveau doctorat » pour GPT-5. Pourtant, depuis son lancement, les retours sont tout autres. L’IA fait des erreurs grossières et des experts alertent à ce propos. Et pour cause, le niveau d’hallucination est élevé.

Pourtant, lors de la présentation de GPT-5, OpenAI avait promis que son IA hallucine moins. La réalité est tout autre. Et sur Reddit, un utilisateur constate que GPT-5 « génère des informations fausses sur des faits de base plus de la moitié du temps ».
GPT-5 n’atteint pas le « niveau doctorat » comme promis par OpenAI
Alors oui, il faut systématiquement vérifier les réponses des chatbots. Mais le fait que ces hallucinations soient fréquentes pose des questions sur la fiabilité de GPT-5, qui a aussi été critiqué pour sa personnalité trop froide. Alors oui, les hallucinations ne sont pas un problème juste pour ChatGPT. Toutes les autres IA en sont victimes, aussi bien Google Gemini que Claude. Mais il semblerait que le chatbot d’OpenAI soit particulièrement enclin à inventer des faits.
Dans un article de blog, OpenAI tente d’expliquer le phénomène. La start-up de Sam Altman affirme que « les hallucinations persistent en partie parce que les méthodes d’évaluation actuelles créent de mauvaises incitations ». Pour faire simple, les tests de mesure des performances encouragent les IA aux suppositions au lieu de l’honnêteté. Une IA qui ignore la réponse préférera inventer que dire à l’utilisateur qu’elle n’en sait rien.
Les modèles de langage hallucinent donc puisqu’ils sont entraînés à donner des réponses correctes, et même si cela leur demande d’inventer. Il existe toutefois des IA qui se distinguent à ce niveau comme Claude qui admet lorsqu’il ignore une réponse, mais ChatGPT, lui, préfère énoncer des faits faux avec une grande confiance au lieu de reconnaître ses limites.
Un test simple montre les limites flagrantes de GPT-5
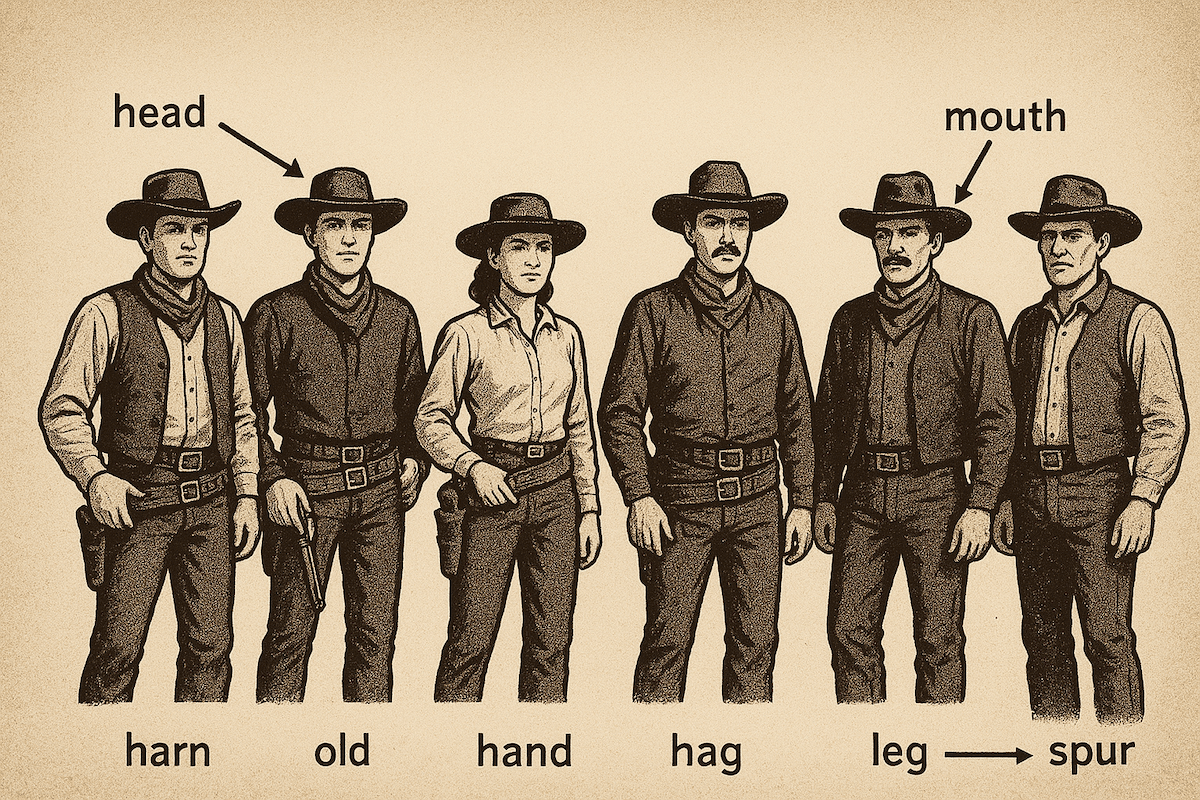
Gary Smith du Walter Bradley Center a mené trois expériences avec GPT-5 pour « démontrer que l’IA est loin d’une expertise de niveau doctorat ». Le chercheur a demandé au chatbot de générer l’image d’un opossum avec cinq parties de son corps étiquetées. Résultat, le nom des parties était correct mais pas leur placement. ChatGPT a indiqué la patte comme le nez et la queue comme la patte arrière gauche. Une autre expérience de Gary Smith demandait à ChatGPT de générer un « possom » avec six parties du corps étiquetées. À noter que l’on parle bien ici de « possom » au lieu de « opossum », une faute glissée volontairement pour constater si correction il y a. L’IA a alors généré une image hors sujet avec six cowboys et des étiquettes étranges.
GPT-5 n’a sûrement pas le niveau d’intelligence d’un candidat au doctorat et on doute même qu’il ait celui d’un lycéen. Bref, la leçon est toujours la même, que ce soit ChatGPT ou n’importe quelle IA disponible sur le marché, vérifiez toujours ce qu’elle vous raconte. Les hallucinations sont fréquentes et les chatbots présentent de fausses informations avec une confiance déroutante.
- OpenAI présente GPT-5 comme “niveau doctorat”, mais de nombreux retours évoquent des erreurs fréquentes, une personnalité froide et des réponses factuellement fausses “plus de la moitié du temps” selon un utilisateur Reddit.
- OpenAI admet que ses évaluations poussent les modèles à répondre même en cas d’incertitude, ce qui favorise les hallucinations au lieu d’un simple “je ne sais pas”.
- Les tests de Gary Smith montrent le décalage avec l’étiquette “doctorat”, avec un opossum mal annoté et une confusion totale après une faute volontaire, d’où la nécessité de vérifier systématiquement les réponses.
Source : Futurism













Un avis, une expérience, un désaccord ? La discussion est ouverte.